대시보드 프로젝트를 마치고 실제 데이터를 넣는 순간, 디자인이 무너지는 경험은 생각보다 흔합니다. 화려한 차트와 정갈한 폰트로 채워진 피그마 시안은 완벽해 보였지만, 실제 운영 환경에서는 사용자의 외면을 받는 경우가 허다합니다. 이는 우리가 데이터를 '채워 넣어야 할 재료'로만 보고, 인터페이스의 '뼈대'로 인식하지 못했기 때문입니다.
왜 데이터 구조가 곧 인터페이스가 되어야 할까요?
데이터의 논리적 흐름이 사용자의 사고 과정과 일치해야만 직관적인 UX가 완성되기 때문입니다. 많은 에이전시가 범하는 실수는 '보기 좋은 레이아웃'을 먼저 잡고 그 안에 데이터를 끼워 맞추는 것입니다. 하지만 데이터 중심 제품에서 사용자는 디자인을 감상하러 오는 것이 아니라, 쏟아지는 정보 속에서 유의미한 패턴을 찾아내기 위해 접속합니다. 데이터의 계층 구조와 관계가 UI의 레이아웃을 결정해야 하며, 디자인은 그 구조를 가장 명확하게 드러내는 도구가 되어야 합니다.
현업에서 대시보드 이탈률이 높은 이유는 대부분 정보의 과잉이 아니라 정보 간의 '맥락 부재'에서 기인합니다. (출처: UX Collective) 데이터가 어떤 비즈니스 로직을 거쳐 생성되는지 이해하지 못한 채 설계된 UI는 사용자에게 해석의 고통만을 안겨줄 뿐입니다. 따라서 설계의 시작점은 캔버스가 아니라 데이터 명세서가 되어야 합니다.
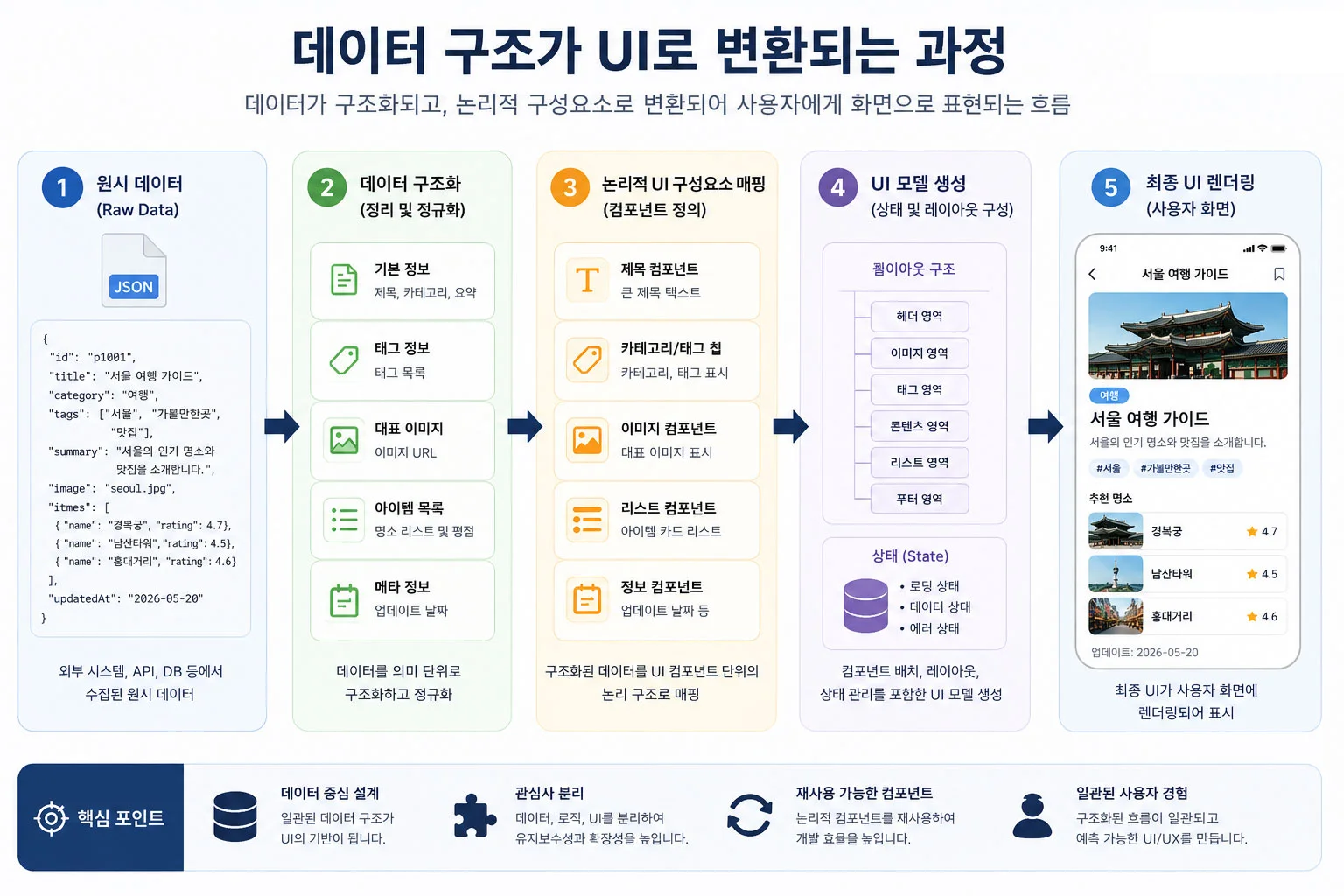
디자이너가 직접 데이터를 만져봐야 하는 이유는 무엇일까요?
도구의 한계를 이해하고 실제 데이터의 불규칙성을 체득해야만 현실적인 설계가 가능하기 때문입니다. 피그마에서 다루는 'Dummy Data'는 언제나 예쁘고 정갈하지만, 실제 데이터는 누락되기도 하고 예상보다 훨씬 길거나 짧을 수 있습니다. 파이썬이나 SQL 같은 언어를 조금이라도 익혀 실제 데이터를 직접 가공해 보는 경험은 디자이너에게 새로운 시각을 제공합니다. 데이터가 어떻게 수집되고 변형되는지 알면, 인터페이스에서 발생할 수 있는 예외 상황을 설계 단계에서 미리 방어할 수 있습니다.
특히 복잡한 SaaS 제품을 설계할 때, 디자이너가 도메인 지식 없이 시각화에만 집중하면 결국 '기능 나열식' 인터페이스에 그치게 됩니다. 직접 데이터를 쿼리해 보며 사용자가 어떤 지점에서 병목을 느끼는지 파악하는 '도그푸딩'의 과정이 필수적입니다. 이는 단순한 기술 습득을 넘어, 사용자가 데이터를 바라보는 관점을 공유하는 과정이기도 합니다.
단순한 시각화와 의사결정 지원은 어떻게 다를까요?
시각화는 현재의 상태를 보여주는 데 그치지만, 의사결정 지원은 사용자가 다음에 해야 할 행동을 제안합니다. 한국의 많은 대시보드 프로젝트가 화려한 그래프를 배치하는 데 급급하지만, 정작 사용자는 "그래서 내가 지금 뭘 해야 하지?"라는 질문에 답을 얻지 못합니다. 진정한 데이터 중심 설계는 데이터를 보여주는 것을 넘어, 데이터 사이의 상관관계를 통해 인사이트를 도출하고 사용자의 의사결정 속도를 높여주는 데 목적이 있습니다.
화려한 UI를 원하는 클라이언트에게 어떻게 대응해야 할까요?
시각적 화려함보다 데이터의 정확한 전달이 비즈니스 성과에 직결됨을 증명해야 합니다. 클라이언트는 종종 경쟁사의 화려한 대시보드를 가져와 비슷하게 만들어달라고 요구합니다. 하지만 알맹이 없는 화려함은 운영 단계에서 반드시 문제를 일으킵니다. 우리는 문제의 본질이 '예쁘지 않은 UI'가 아니라 '데이터를 활용하지 못하는 구조'에 있음을 짚어주어야 합니다. 비즈니스 목표를 달성하기 위해 필요한 핵심 지표가 무엇인지 먼저 정의하고, 그 지표가 가장 잘 보이도록 설계하는 것이 에이전시의 진짜 역량입니다.
실제 데이터를 활용한 와이어프레임은 어떻게 시작할까요?
더미 데이터 대신 클라이언트의 로우 데이터를 프로토타입에 직접 주입하는 시나리오를 설계해야 합니다. 프로젝트 초기 단계부터 실제 데이터의 일부를 가져와 와이어프레임에 적용해 보세요. 텍스트 길이가 제각각인 상황, 특정 데이터가 0일 때의 차트 모양, 수치가 급증했을 때의 가독성 등을 미리 확인해야 합니다. 이 과정에서 디자인의 논리적 결함이 발견된다면 그것은 실패가 아니라 설계를 고도화할 수 있는 가장 빠른 기회입니다.
만약 특정 도메인의 데이터가 너무 복잡해 이해하기 어렵다면, 클라이언트의 실무자가 데이터를 분석하는 과정을 옆에서 지켜보는 것부터 시작하십시오. 그들이 엑셀에서 어떤 필터를 자주 쓰는지, 어떤 수치를 비교하는지 관찰하는 것만으로도 인터페이스의 우선순위는 명확해집니다. 정답을 찾으려 하기보다 사용자가 데이터를 다루는 '방식'을 관찰하는 데 집중해 보시기 바랍니다.
데이터 중심 설계는 단순히 정보를 예쁘게 보여주는 기술이 아닙니다. 데이터의 구조를 깊이 이해하고 이를 인터페이스의 논리로 치환하는 과정입니다. 이제 피그마를 켜기 전에 엑셀 시트나 데이터베이스 구조를 먼저 들여다보는 습관을 가져보세요. 데이터가 스스로 말을 걸기 시작할 때, 비로소 사용자의 의사결정을 돕는 진짜 인터페이스가 탄생합니다.
개념적 토대 및 참고: UX Collective (https://uxdesign.cc/designing-data-intensive-applications-advice-for-interaction-designers-d87ec435cb8b?source=rss----138adf9c44c---4)
본 글은 위 원문의 핵심 개념을 바탕으로, Pivot Studio의 실무적 관점과 해석을 더해 재구성한 오리지널 콘텐츠입니다.